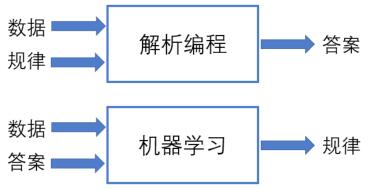
“炸街车”抓拍系统启用背景 随着城市车辆保有量的不断增加,交通噪声已经成为城市噪声的主要来源,尤其是运动型跑车或经非法改装的汽车所发出的“声浪”,即轰鸣声。轰鸣声扰民严重,具有高度危害性,因此,这类车辆被形象地称作“炸街车”。本文介绍基于声呐的“炸街车”电子自动抓拍系统的构成、工作原理、取证方法、证据呈现方式,并通过深度学习、声呐阵列定位等技术,有效解决了“炸街车”的自动识别和判定;实际运行的系统表明本方法的检测效果较理想,为后续研制更稳定可靠的电子抓拍系统奠定了坚实的基础。 “炸街车”抓拍系统的研究 依据国家城市区域环境噪声标准, 交通干线两侧的环境噪声标准值为昼间70分贝、夜间55分贝。而经过非法改装的“炸街车”,猛轰油门或者急加速的时候,发动机、排气筒都会发出巨大声响,典型分贝值区间高达80~110分贝,严重影响附近居民正常生活,扰乱正常的车辆通行秩序,且非法改装的车辆存在较大交通安全隐患。“炸街车”属于交警严厉查处的违法行为,但一直没有得到很好的执行,原因是噪声超标行为难以取证,相关取证无法实现自动化。民警通常通过守候拦截查处 “炸街车”,但守候拦截的效率低且有安全隐患。为躲避处罚,有的车辆安装了切换器,遇到交警查处时则切换成普通模式,排气管不会发出轰鸣声,大大增加了查处难度。因此,为了有效遏制“炸街车”的扰民行为,急需引入先进技术,实现对“炸街车”查处电子化和自动化。 2016年以来,多地交警部门与企业合作,试点采用违法鸣笛抓拍系统,对机动车鸣笛行为进行自动取证抓拍。违法鸣笛抓拍系统通过声呐定位出鸣笛车辆,控制高清摄像机对违法车辆进行抓拍。违法鸣笛抓拍系统已经在全国六十多个城市得到应用,取得了显著的效果。本文使用违法鸣笛抓拍系统类似声音定位技术,结合深度学习算法的多通道声音信号感知分类技术,以准确抓取“炸街声”,实现对“炸街车”的全天候、全时段自动抓拍。 相关技术研究 基于深度学习的“炸街车”声感知技术 “炸街车”不同于机动车鸣笛,判断是否有“炸街车”更具挑战性。汽车鸣笛声比较单一,时域和频域特征明显,和环境中常见的各种背景噪声区别较大;“炸街车”声音种类繁多,不同车型、不同改装方法,声音特征有很大的区别,通过传统的声学信号处理方法进行分类很容易产生误判。 基于神经网络的机器学习技术的关键思想是,将人为设计的规律,替换为使用分层网络从训练数据中学习的规律机器学习与传统处理方法的典型区别是,不需要先验的数学物理知识,通过输入训练数据,使用反向传播算法来指示神经网络模型如何改变其内部参数,由多个神经网络层组成的计算模型来学习系统的内在规律。机器学习与传统方法的流程区别如图1所示。 图 1 传统方法和机器学习的流程区别 近年来随着计算性能的持续提高、模型的持续优化和可用数据量的指数级增长,深度神经网络(DNN)在不同的分类任务中表现出令人难以置信的结果,该技术大大地提高了语音处理、图像识别等诸多领域技术水平。机器学习具备更快的推理和执行复杂认知任务的能力,而不需要专业知识和经验。本文尝试将深度学习技术应用在“炸街车”声音的智能检测中,主要研究内容为“炸街车”数据的收集和标记、深度学习神经网络的建立、自动抓取的实验验证。 数据的收集和标记 本文采用的方法是将“炸街车”判断转换成监督学习问题。监督学习是从标记的训练数据来推断一个功能的机器学习任务,训练数据包括一套训练示例。在监督学习中,每个实例都由一个输入对象和一个期望的输出值(也称为一维数组,标记每一帧声音的种类)组成,每帧数据根据所需的分段进行分类,常用的分类有:“炸街车”、鸣笛、刹车、警报、背景噪声等,如图2所示。人为地将经麦克风采集到的不同时间段的声音分成几类,从而指导深度学习网络进行误差反向传播,学习到合适的参数。 图 2 监督学习的数据标注 本文共收集了约2000组“炸街车”音频信号,和约4000组其他类型声音信号。为了获得更好的训练效果,通过数据增强来丰富音频的变化,提升数据的数量和多样性,使用的方法包括时移变换(timeshifting)、速度调整(speed tuning)、混合背景音(mix background noise)和音量调节(volumetuning)、增加白噪声(adding white noise)、移动 音 频(shifting the sound)、 拉 伸 音 频 信 号(stretching the sound)等。 深度学习神经网络的建立 本文采用了基于卷积的深度学习神经网络结构。卷积神经网络(CNN)通过使用卷积操作来学习输入矩阵元素点之间的关系,从而提取特征。CNN具有主要以下三点优势:首先内核权重分享机制有助于处理高维数据(2D图像或3D数据);其次矩阵元素的局部特征可用2D或3D内核来获得;最后使用池化层可以实现轻微的平移不变性增加系统鲁棒性。典型的CNN结构如图3所示,主要包含:卷积层、非线性激活层、池化层等。 图 3 卷积神经网络结构 本文所用神经网络在训练过程中误差函数收敛如图4所示,数据收敛,表明训练数据有效。 图 4 损失函数训练收敛过程 神经网络训练完成,输入新的声音信号,神经网络利用学习的参数则可自动判断哪段信号属于“炸街声”,从而自动触发抓拍系统进行工作。如图5所示,曲线代表预测是“炸街声”的概率,当超过认为设定的判断阈值(虚线)时即开始触发,蓝色实线为人工标注的区域。数据显示人工和机器自动判别二者吻合度较高。 图 5 神经网络预测“炸街声”结果 声源定位系统的原理 深度学习系统准确判断识别出“炸街车”的声音信号后,选取该段信号输入到声呐的声源定位系统,准确获得车辆位置,用高清摄像机抓拍“炸街车”声源位置的车辆照片并识别车牌号码,将声压分布与照片和视频进行叠加形成“炸街车”声超标证据,即“声音云图”和“声音视频”,抓拍到的车辆号牌可在现场LED显示屏上公示并推送到执法后台进一步核实和处理。 在“炸街车”抓拍系统中使用的“声呐”,其准确的学术名称叫“麦克风阵列”,是由多个麦克风按照一定规律排布组成的一种设备。使用单个麦克风进行录音,无法区分声音来源于哪个方向;多个麦克风的使用使得麦克风阵列有区分方向的能力,就如人因为有两个耳朵,所以能够判断声音来自哪个方向一样,如果一个耳朵丧失听力,则听音方向性差很多。“炸街车”取证难的原因就在于,听到声音但没有一种客观的技术手段知道声音来自哪个位置。麦克风阵列技术的出现解决了对“炸街车”噪声取证难的难题,可以直观地将“炸街声”可视化。如图6所示,是上海其高科技设计制造的一款典型的声呐,是由很多个麦克风按照一定规律排布形成的设备。 […]
新闻中心
-
 关于“炸街车”自动抓拍系统探索2019-10-22
关于“炸街车”自动抓拍系统探索2019-10-22 -
 违法鸣笛抓拍系统生产厂家比较
违法鸣笛抓拍系统生产厂家比较违法鸣笛抓拍系统是麦克风阵列声源定位的应用,其中最主要的技术就是能否把汽车鸣笛声定位准确,当然还有车牌识别等其他必要技术。 全国声称能够提供鸣笛抓拍解决方案的供应商不少,但真正在市场上大量使用的也就只有其高科技一家。直辖市省会城市和各主要城市绝大多数采用其高鸣笛抓拍系统产品。 鸣笛抓拍是一个相对综合的应用领域,尤其是稳定性和抗干扰能力,很多新厂家号称很高的准确率,但那是在实验室测的,一到真正的使用现场就原型毕露。 1. 违法鸣笛抓拍系统波束形成工作原理 违法鸣号抓拍系统是一种声源定位取证设备,包括高清智能摄象机、工控机、空气声呐(声学探头、麦克风阵列、声学照相机)、补光灯、LED显示屏等。违法鸣笛抓拍系统作为一种新型的电子警察取证设备,通过波束形成声源定位技术对乱鸣喇叭不文明行为进行取证。 违法鸣笛检测设备的空气声纳具有非常高的声音定位分辨力,含有几十个麦克风,每个麦克风均是高灵敏度MEMS麦克风,能探测到几十米远的微弱声音,几十个麦克风集成在一起,由信号处理算法计算每个声音信号的时间差,从而可反推出鸣笛声的发生位置。禁止鸣喇叭抓拍系统的高清摄象机配置根据具体的安装地点进行配置,车道数不同可配备不同分辨率的智能相机,一般使用200万像素到1200万像素的相机,高清摄象机内置智能芯片,可根据声学相机的声音定位抓拍图片,对图片中的违法车辆的车牌进行识别。 违法鸣笛抓拍系统通过主控机与违法处理平台进行协议对接,按照违法处理平台的协议规范,将高清图片和视频推送到违法处理平台服务器,并在违法鸣笛抓拍系统安装地点现场的LED显示屏上违法鸣号行为车辆号牌。乱鸣喇叭记录系统自2017年投放到市场以来,已经获得了大量的验证检验,适用于全国各个省份,从最南方的海南到最北的黑龙江,从平原到高原(西藏),违法鸣笛抓拍系统均已稳定运行一年以上,产品质量获得交警部门的认可。 违法鸣笛抓拍系统设计方案 2. 违法鸣笛抓拍系统最佳安装地点和安装方法 违法鸣笛抓拍系统的安装非常便捷,一般2小时即可完成全部的安装调试工作,具体与现场具备条件有关。 使用钢扎带或抱箍将声学探头、高清摄像机固定在电子警察横杆上,将配电箱固定在立杆上,按照其高鸣笛抓拍系统使用手册进行线路连接和调试即可完成安装工作。鸣笛抓拍系统安装之前需要确认供电和视频专网接入条件,安装时需要高车、梯子、吊绳等工具。违章鸣笛抓拍系统安装路段的选择一般应结合一线民警的经验进行选择,虽然一般来讲车流量大的地方在禁止鸣笛路段鸣喇叭行为将呈现多发态势,有必要安装违法鸣笛抓拍系统,但各地的选择原则仍然可能有所不同。有些城市市民素质相对较高,一般情况下不会鸣笛,因此只需在交通一拥堵路段且对市民生活工作影响较大区域进行安装即可,而有些城市不文明驾驶行为较常见,有些驾驶员习惯性地进行违法鸣笛,则需要以单位性质和投诉多发点为主来选择安装点位。 乱鸣喇叭记录系统的安装过程类似于卡口相机的安装,首先将声呐、卡口智能相机、补光灯固定在横杆上,配电箱固定在立杆上,上电后调好高清相机的角度、焦距、光圈等,接着调整空气声纳的角度,与高清相机的拍照范围进行匹配,按照车辆违章鸣笛抓拍系统的使用手册进行简单参数配置即可完成安装。 乱鸣喇叭自动记录系统的总体设计便于安装,单个设备轻巧方便运输,声呐不大于5公斤,全铝外壳、IP65防护等级,如有特殊要求,可升级到IP76。摄象机则是使用主流品牌卡口相机,重量一般不大于5公斤,符合室外使用要求。空气声呐大小尺寸不大于40x30x25cm,安装空间不小于50cm即可。 乱鸣喇叭自动记录系统可以安装在一至五个车道的路口路段,比较常见的是安装在2~4个车道的路段。对于车道多于五个车道的路段,也可以根据安装位置实现对部分车道进行抓拍。对于五车道路段,一般可以选择安装在中间车道上方横杆上,如果该位置不便安装,也可以安装在其他车道上方,通过调整声呐和高清相机的角度,实现对五个车道的覆盖。违法鸣笛抓拍系统的安装过程中,需要考虑的另外一个重要因素就是对乱摁喇叭行为的有效抓拍区域。声学探头和高清摄像机的角度需配合安装杆件的高度进行适当调节,调节相机的光圈和焦点,校验声呐和高清摄像机的坐标转换关系。
2019-10-21 -
 长沙乱鸣喇叭抓拍系统生产厂家有哪些
长沙乱鸣喇叭抓拍系统生产厂家有哪些其高科技是最早使用MEMS麦克风阵列对乱鸣喇叭违法行为实行抓拍的技术方案供应商,其高违法鸣笛抓拍系统已经在全国一百多个城市实施,经过长时间各种天气条件的验证,长期稳定运行,准确率被用户高度认可,已经在几十个城市被用于非现场执法,对在禁止鸣喇叭区域乱按喇叭违法行为形成强大的威慑作用。 如何正确选择鸣笛抓拍供应商? 1. 长沙乱鸣喇叭抓拍系统定位鸣笛声的方法原理 禁止鸣喇叭抓拍系统是智能交通高科技前端设备,能够准确自动记录乱摁喇叭行为行为,通过声学探头(麦克风阵列、空气声呐)、高清摄象机、主控机、LED显示屏等设备组成一整套完整的抓拍系统。汽车违法鸣笛抓拍系统的出现,使得对乱按喇叭行为行为进行自动取证成为可能,可对在禁鸣区域乱鸣喇叭车辆进行非现场处罚。 违法鸣笛抓拍系统使用声学探头判断声音的来源方向,对鸣笛噪声定位。声学探头的工作原理与水下声呐探测敌方舰艇的原理一样,因此声学探头也叫空气声呐,是声呐鸣笛抓拍系统的核心部件。违法鸣笛抓拍系统检测到鸣笛声并通过算法获得鸣笛声音的准确定位后,触发高清相机将鸣笛车辆以及号牌进行捕获,接下来系统以第一时间将所抓拍到的数据通过现场交通专有网络推送至交警的后台,这里推送的数据不仅仅包含传统电警抓拍的高清图片,还包括了一段几秒钟的视频,视频中可以回放被抓拍车辆在现场的鸣笛全过程,在视频中不仅可以看到现场的环境、鸣笛的动机、车辆的行为,更可以记录现场的声音,尤其是鸣笛车辆的喇叭声音,以作为进一步的证据。 违法鸣笛抓拍系统的主控计算机协调控制声学探头和高清摄象机,分别获得同步的声音和视频,合成处罚证据,将必要的证据图片和视频推送到后台或手机前端。违法鸣笛抓拍系统产品生成的声音视频是其特色之一,是现场声音环境的真实再现,声音与图片的同步达到完美无延迟,是乱按喇叭行为行为的良好证据。其高科技首先创新性地将声音视频作为违法鸣笛证据提供给交警,获得了普遍的认可和很高的评价。违法鸣笛抓拍系统是能够生成真实声音环境声音视频的产品。其他竞品生成的声音视频实际上仅仅是简单模仿,不能完全再现鸣笛过程。 长沙乱鸣喇叭自动抓拍系统生成 2. 长沙乱鸣喇叭抓拍系统安装在F杆上吗,需要多大空间? 禁止鸣喇叭抓拍系统的安装过程与一般的电子警察取证系统的构成类似,用钢扎带或抱箍将空气声呐、高清摄象机、补光灯固定在横杆上即可,一个电源线和网线连接到控制箱即可,软件设置简单快捷,无需具备声学知识也可轻松完成安装任务。违法鸣笛抓拍系统通常安装在学校、医院、住宅区、科研单位、机关等单位周围的路段路口。对过往车辆乱鸣喇叭行为进行严格处罚,并在主流媒体上进行宣传,对违法车辆经常性地进行曝光,将大大提高违法鸣号抓拍系统的威慑力,为学校、医院等单位提供良好的安静环境。 安装机动车违法鸣笛抓拍系统的过程一般来说,在2~3小时内可以完成,尤其对于熟悉电子警察设备安装的工程师来说,所需时间更短。另一方面讲,供电、网络接入条件对于汽车违法鸣笛抓拍系统来说有时比安装更重要,只要具备供电和网络接入条件,鸣笛声呐电子抓拍系统的安装和调试均很快可以完成,可以做到“今晚安装明天启用”。汽车违法鸣笛抓拍系统重量轻、个头小,对安装条件的适应性强。安装过程一般需要2~3人配合,2~3小时可以完成整个系统的安装调试,即时实现违法鸣笛抓拍。声纳和高清相机可以斜向安装,无需与道路平行,安装更加灵活,可以在各种路口路段利用已有的电警杆件或红绿灯进行安装。 违法鸣笛抓拍系统对车道的覆盖主要根据高清智能相机的配置,配备700万高清卡口智能相机,可以覆盖不超过4个车道,配备900万相机,则可以覆盖不超过5个车道,配备1200万相机,可以覆盖6个车道。其高声纳本身的声源定位检测范围比高清摄象机大,因此,整个鸣笛抓拍系统的抓拍车道数主要取决于高清摄象机。乱鸣喇叭抓拍系统中使用的高清摄像机多为卡口相机,卡口相机的标准安装调试是只是把二十多米处经过车辆的清晰度和捕获率调好,由于卡口相机的应用相当成熟,基本上不需要什么调试。然而,把它应用在违法鸣笛抓拍系统上时,需要兼顾整个抓拍区域内的图片清晰度,鸣笛抓拍系统的有效抓拍区域比卡口相机的捕获区域要大得多,因此在安装时,需要重点关注高清摄像机在有效区域内的清晰度调试。 长沙违法鸣笛抓拍系统完整技术方案(价格报价清单)
2019-10-19 -
 乱鸣喇叭抓拍系统需要多久完成安装,影响交通吗?
乱鸣喇叭抓拍系统需要多久完成安装,影响交通吗?乱鸣喇叭抓拍系统需要多长时间完成安装,影响交通吗? 其高乱鸣喇叭抓拍系统的安装非常简便,相对于普通卡口或者电警的安装来说,只需要多装一个声学探头即可,而其高的声学定位探头因为中央集成了一个摄像头,因此可以快速的将探头所抓拍的范围与高清相机中的视角相匹配并校准,系统可以自动实现对声学相机中的声音定位坐标与高清相机中的图像坐标进行匹配,从而保证了实现定位的准确性。因此其高乱鸣喇叭抓拍系统的整体安装时间在1~2小时以内,如果不装LED号牌显示屏的话。这也是探头集成摄像头的重要优势所在。 鸣笛抓拍安装方式之一——F型杆件上 其高乱鸣喇叭抓拍系统安装路段的选择,一般根据现场勘探和市民需求反映来确定。根据目前其高乱鸣喇叭抓拍系统在全国一百多个城市安装地点的选择来看,各市选择在学校、医院附近的较多,也有选择安装在红绿灯路口等交通繁忙乱鸣喇叭常见区域。 鸣笛抓拍安装的区域 鸣笛抓拍系统一般安装在F型杆件上,系统中的空气声呐、高清相机、补光灯一般安装在横杆上,补光灯根据车道数配置,一般用2~3个。新型杆件一般都有固定槽,只需使用螺丝把设备锁紧在固定槽上即可。LED显示屏的固定需要使用与显示屏配套的原装抱箍固定在立杆上,固定完后用六类网线连接到交换机上。配电箱使用抱箍固定在立杆上。配电箱和LED显示屏的安装高度应注意不会对行人和过往车辆造成影响,尤其应注意LED显示屏有没有可能被公交车撞上。 其高乱鸣喇叭抓拍系统中的麦克风阵列(声学探头)、高清摄像机、LED显示屏、主控机之间的连接通信通过以太网实现,由于数据量比较大,对通信质量要求高,最好使用六类网线和千兆交换机。网线总长度约30米,不含交换机到视频专网接入点的距离。LED显示屏重量不大于80公斤。其高乱鸣喇叭抓拍系统安装和使用高度标准为6.5米,实际实施时,实际高度有所变化也问题不大。 鸣笛抓拍现场安装图 鸣笛抓拍系统可适应多种使用场景,自带的配置软件可以根据现场安装完成后的场景进行适配。调整安装角度可以在清晰度和抓拍范围间获得比较好的均衡。其高乱鸣喇叭抓拍系统中使用的高清摄像机多为卡口相机,卡口相机的标准安装调试是只是把二十多米处经过车辆的清晰度和捕获率调好,由于卡口相机的应用相当成熟,基本上不需要什么调试。然而,把它应用在违法鸣笛抓拍系统上时,需要兼顾整个抓拍区域内的图片清晰度,鸣笛抓拍系统的有效抓拍区域比卡口相机的捕获区域要大得多,因此在安装时,需要重点关注高清相机在有效区域内的清晰度调试。 鸣笛抓拍系统中的声学探头
2019-10-16 -
 长沙乱鸣喇叭抓拍系统的原理
长沙乱鸣喇叭抓拍系统的原理自2019年9月开始,长沙交警正式在启动机动车违法鸣笛抓拍系统,该自动鸣笛抓拍系统可以准确定位乱鸣喇叭的机动车,并将抓拍到的违法鸣笛车辆号牌实时推送到路口LED显示屏上,以警示违法人员。 一直以来,违法鸣笛抓拍的查处存在一定难度,因为车辆鸣笛声音稍纵即逝,存在辨认难、取证难等问题。现在,基于声源定位的违法鸣笛抓拍系统上线工作,将帮助交警通过科技管理手段对乱鸣笛的车辆进行抓拍、处罚。 那么,乱鸣笛喇叭抓拍原理是什么呢? 其高乱鸣喇叭抓拍系统主要由声源定位、车牌抓拍识别、后台执法联动多个子系统联动构成。声源定位子系统主要是麦克风阵列(或声呐、空气声呐),车牌抓拍识别子系统由700万或更高像素智能摄像机完成,后台执法联动则是运行在工控机上的定制软件。 乱鸣喇叭抓拍系统可以说是一种特殊的声学照相机。声学照相机一般用于汽车、航空航天、家电等产品研发的异音异响定位,鸣笛抓拍是声学照相机在交通领域的扩展应用。其高科技的乱鸣喇叭抓拍系统,是基于声源定位技术进行的再次开发。该技术主要是通过多个麦克风对特定声音进行采集,先是计算声音到达麦克风的时差,通过时差与麦克风布阵方式的特性,再计算得出实际发声位置的信息。 其高科技自主研发的声学相机(麦克风阵列) 乱鸣喇叭抓拍系统声源定位子系统根据声源定位和声纹识别,控制高清摄像机捕获违法鸣笛车辆的高清图片,夜间还控制补光灯以便保证图片质量。通过智能相机的SDK获取抓拍图片中的全部车牌号码,并与声音定位位置进行匹配,筛选乱鸣喇叭车辆。 鸣笛抓拍系统生成的取证图片 乱鸣喇叭抓拍系统的主控计算机协调控制声学探头和高清摄像机,分别获得同步的声音和视频,合成处罚证据,将必要的证据图片和视频推送到后台或手机前端。 其高乱鸣喇叭抓拍系统的产品设计适合恶劣的户外环境全天候使用,即使经历了”山竹“这样的强台风后依然正常工作。对刹车、救护车、风雨等各种干扰声音能够自动排除,强大的声纹识别能力保证其高乱鸣喇叭抓拍系统的违法鸣笛抓拍准确率。
2019-10-16 -
 太原鸣笛抓拍系统按一下喇叭也会被拍吗?
太原鸣笛抓拍系统按一下喇叭也会被拍吗?太原违法鸣笛抓拍系统在禁止鸣笛路段对违法乱鸣喇叭行为实施自动抓拍,捕获率和准确率都在95%以上。太原鸣笛抓拍系统根据声音声纹特征对违法鸣笛车辆实施抓拍,每40毫秒计算一次,原则上任何乱鸣喇叭行为均被记录,因此,按一下喇叭也将被抓拍。 其高是违法鸣笛抓拍系统产品开发的先行者、标准起草者,产品稳定可靠,已经在全国一百多个城市安装使用。 了解更多关于鸣笛抓拍系统的设计方案、安装方案以及价格…… 1. 太原违法鸣笛抓拍系统是如何实现对乱鸣喇叭车辆准确抓拍的 其高违法鸣笛抓拍系统通常由声学探头、高清相机、现场工控机、LED号牌显示屏等主要部件组成,其中核心的部分是声学探头,往往又被称做麦克风阵列、声呐、空气声呐等等。违法鸣笛抓拍系统可以说是一种特殊的声学照相机。声学照相机一般用于汽车、航空航天、家电等产品研发的异音异响定位,鸣笛抓拍是声学照相机在交通领域的扩展应用。其高太原违法鸣笛抓拍系统使用声学探头判断声音的来源方向,对鸣笛噪声定位。声学探头的工作原理与水下声呐探测敌方舰艇的原理一样,因此声学探头也叫空气声呐,是违法鸣笛抓拍系统的核心部件。 太原违法鸣笛抓拍系统检测到鸣笛声并通过算法获得鸣笛声音的准确定位后,触发高清相机将鸣笛车辆以及号牌进行捕获,接下来系统以第一时间将所抓拍到的数据通过现场交通专有网络推送至交警的后台,这里推送的数据不仅仅包含传统电警抓拍的高清图片,还包括了一段几秒钟的视频,视频中可以回放被抓拍车辆在现场的鸣笛全过程,在视频中不仅可以看到现场的环境、鸣笛的动机、车辆的行为,更可以记录现场的声音,尤其是鸣笛车辆的喇叭声音,以作为进一步的证据。违法鸣笛抓拍系统同步记录声音和高清视频后,自动生成声成像视频和声成像图片作为违法证据,全程记录鸣笛过程,违法行为一目了然。 其高违法鸣笛抓拍系统已通过公安部权威检测部门的检测,获得检测报告。同时也在多个省份的计量检测部门进行检测合格后投入使用,产品对违法鸣笛抓拍的客观性和权威性得以保证。 其高鸣笛抓拍系统工作原理 2. 太原违法鸣笛抓拍系统需要什么安装条件,供电功率多大? 其高违法鸣笛抓拍系统安装简单快捷、位置灵活、连线简单、无需做声学标定,通常两个人两个小时即可完成主体设备的安装调试,即时具备违法鸣笛抓拍能力。其高太原违法鸣笛抓拍系统安装路段的选择一般应结合一线民警的经验进行选择,虽然一般来讲车流量大的地方乱鸣喇叭将呈现多发态势,有必要安装违法鸣笛抓拍系统,但各地的选择原则仍然可能有所不同。有些城市市民素质相对较高,一般情况下不会鸣笛,因此只需在交通一拥堵路段且对市民生活工作影响较大区域进行安装即可,而有些城市不文明驾驶行为较常见,有些驾驶员习惯性地进行违法鸣笛,则需要以单位性质和投诉多发点为主来选择安装点位。 其高违法鸣笛抓拍系统的安装过程与常用的电子警察设备安装过程类似,需要在交警部门进行报备,对交通道路进行适当的提前警示或封堵,确保安装过程的安全性。安装过程一般需要两个人进行配合,核心部件的安装、连线、调试一个人即可完成。空气声纳、高清摄像机、补光灯的安装一般一个人即可以完成,配电箱、LED显示屏需要至少两个人进行配合。各个部件的安装方法和软件配置,参考其高违法鸣笛抓拍系统使用手册完成。其高违法鸣笛抓拍系统的总体设计便于安装,单个设备轻巧方便运输,声呐不大于5公斤,全铝外壳、IP65防护等级,如有特殊要求,可升级到IP76。摄象机则是使用主流品牌卡口相机,重量一般不大于5公斤,符合室外使用要求。空气声呐大小尺寸不大于40x30x25cm,安装空间不小于50cm即可。 其高违法鸣笛抓拍系统比较常见地安装在3~4车道的路段或路口,对于多于4个车道的道路,也可以配置更高分辨率的高清相机实现更多车道的覆盖,其高声学探头(声呐)配置的MEMS麦克风多,抗干扰能力强,可以覆盖6个车道。另外,其高声学探头还可设置敏感区域,对于区域外执行更多的降噪处理滤波算法,从而提高抗干扰能力。其高违法鸣笛抓拍系统根据需要抓拍的区域,设置安装点,根据安装点位的距离,选择合适的高清摄像机镜头。如果选用标准镜头,则抓拍区域离安装杆件投影点距离在15米-40米之间。如果要求抓拍区域在五六十米,则可以选用长焦镜头。违法鸣笛抓拍系统的总功率为200~800瓦,具体与工作状态有关。 其高鸣笛抓拍系统施工方案
2019-10-14


沪ICP备10043233号-1
